Admin Edit: The first 12 posts were moved from the referenced thread below due to being off-topic.
No.
https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/
No.
https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/
Ohh, look at you smarty… Linking pages from the internet without reading them. Let’s see:
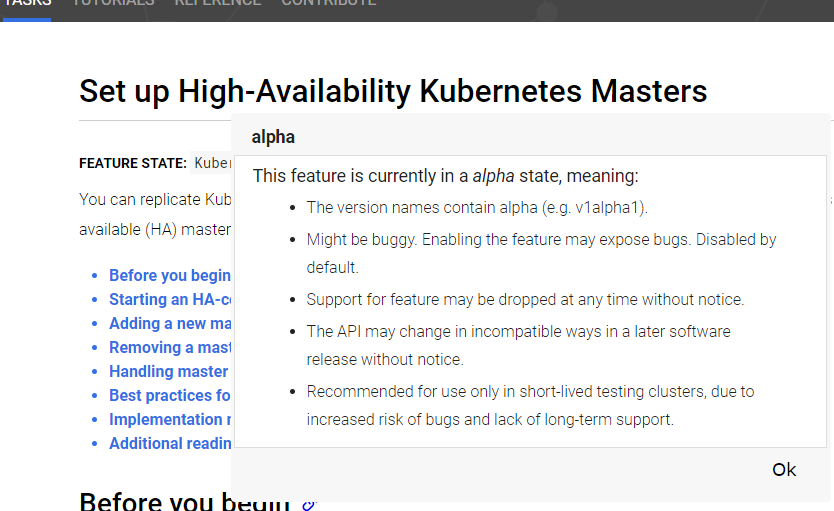
It’s currently in Alpha for one.
Two… the complexities required in setting this up on something outside of Google Cloud or other built-in solutions like we are doing here is extra fun!
At this point… you will also need an HA load balancer too.
With all these extra complexities you will likely experience even further issues.
So I stand by my previous post:
“However, you are adding a single point of failure in regards to the master. Master goes down…everything crawls to a stop.”
I just didn’t specify the lengthy steps to resolve this single point of failure using an Alpha feature.
Being a bit more polite really doesn’t hurt especially not if you don’t have a clue about the background or expertise of someone else.
Sure. There’s other ways of setting up redundant masters other than using the Kubernetes one (like setting up an etcd cluster), just didn’t bother to put any effort in my previous post as it didn’t seem to be worth it. Rightly so I’d say.
Complexity does not equal impossibility. So I’ll just ignore that part since it doesn’t add anything to our discussion. The fact that it’s not a one click deployment doesn’t make it impossible, simple as that.
This goes the same for you. A “No” after linking a page isn’t kind either. It also doesn’t go into the complexities that are involved. It didn’t go into this being an Alpha feature that is suggested for only “testing.”
This doesn’t resolve other issues in regards to HA of the master. An ETCd cluster just makes the ETCd key-store highly available.
Actually it does add things to this discussion. A goal of most system administrators is to reduce complexity in a deployment. Adding complexity makes your setup harder to maintain.
I never mentioned anything about one click. I never said it was impossible. I said it was “extra fun”.
A simple “No” isn’t unkind, it’s just blunt. Either way, let’s keep things civil here please guys.
And again there’s other ways to solving those issues, etcd being part of that. It’s really not that difficult to setup so I don’t understand the fuss here.
This discussion is about you saying that kubernetes masters cannot be redundant. It’s not about how added complexity may or may not make setups harder to maintain.
… and again, you are giving short answers. Before it was just make the key-store highly available, but there are more steps.
No.
This is a discussion about “know if one used k3s in production and get some feedback?”
Which they strip out the Alpha feature set of Kubernetes. Though it does look like they are working on deploying HA for k3s.io Initial "v1" HA Support · Issue #618 · k3s-io/k3s · GitHub.
So what do you expect me to do? Write a complete tutorial or essay on how to setup master redundancy in Kubernetes? I’ve given you at least two options on how to do it, that should be sufficient to back up my statements. On the contrary, you have posted zero things to back up yours. So why don’t you?
No, this discussion is not about k3s anymore. You put down the statement that masters in Kubernetes are a single point of failure which I challenged. I’ve pointed out repeatedly that your statement is false and there are multiple ways to prevent the master from being a single point of failure of which I named at least two as I already pointed out before in this post.
So you either man up and stick to our discussion rather than throwing out empty statements like this or this discussion is over and I wish you a very happy life going around claiming Kubernetes masters are a single point of failure and let anyone else reading this jump to their own conclusions.
No, I said…
However, you are adding a single point of failure in regards to the master. Master goes down…everything crawls to a stop.
I didn’t say Kubernetes couldn’t be highly available.
I have a very valid point in regards to my statement. Without making your master highly available a master going offline will bring your workers and pods to a crawling stop. Can you say I am wrong on this? I’ve tested this without having HA and my cluster came to a crawling stop. My single master node was a single point of failure.
As such, the master is critical to the infrastructure. Without making it highly available it is a single point of failure.
Which is exactly what I said… “You are adding a single point of failure in regards to the master (( Singular, not plural )).” As such, a “Master (( Singular, not plural )) goes down… everything crawls to a stop.”
No, that definitely doesn’t make you wrong. What makes you wrong is that you mention the master being a single point of failure which it’s not if it’s properly made highly available which any cluster should have without any doubt. That’s like saying a slave is a single point of failure which it can be if it’s just that one slave, but it’s completely irrelevant to the context of the rest of your post just as much as the master reference.
So either I completely misinterpreted your post or your post is wrongly worded. Judging by our conversation I’d assume this is just another attempt to dodge the discussion by starting to switch the context of your post. But that’s me.
Does it honestly matter? By default, a master node is a single point of failure unless you deploy a highly available master. Case closed.
Properly is the keyword here. Not everyone understands that the masters need to be HA. People have been given the assumption that Kubernetes provides HA to your entire stack. Which by all means it can, It can do it really well. However, the master needs to be setup with HA. Which by default many are not.
For example:
As such places are providing single master nodes in regards to Kubernetes and they are and can become a single point of failure.
Further, most guides on Kubernetes do not provide HA for the master. The master is left as a single and as such, it is a single point of failure in your cluster. You can lose a whole worker node, and the master will work on redeploying the pods to another worker. If you lose the only master other wonkyness will occur. Like in my case nginx-ingress just stopped handling requests because it didn’t know where to route the requests in the backend.
So with that knowledge… my statement is accurate.
… unless you make the master highly available.
And you think it really helps if you go around saying they’re not without specifying any argument as to where and what? The fact that DigitalOcean doesn’t provide it is a bummer but still doesn’t make your statement valid if that info is in the back of your head but not included in your post where you put an explicit statement like that.
With that knowledge. Sure. That’s why you should have added that knowledge to your post.
If I go around saying slaves are a single point of failure I make sure to mention that I’m using minikube on a single VM, else that statement is just as invalid as yours if you don’t add the context.
Which leads me to my previous post:
I am usually the SPOF.
so…