Having a bit of a conundrum with a new machine I just inherited (the machine that replaced the last dedi that I had issues with and made a thread about). This has occurred twice, so it’s only a matter of time before it occurs again unless I can find a fix or conclude that I have a bad disk…
About a week ago, my server went unresponsive. When logging into IPMI, I found a ton of read/write errors indicating issues with the raid array. Here’s what I saw in remote console:
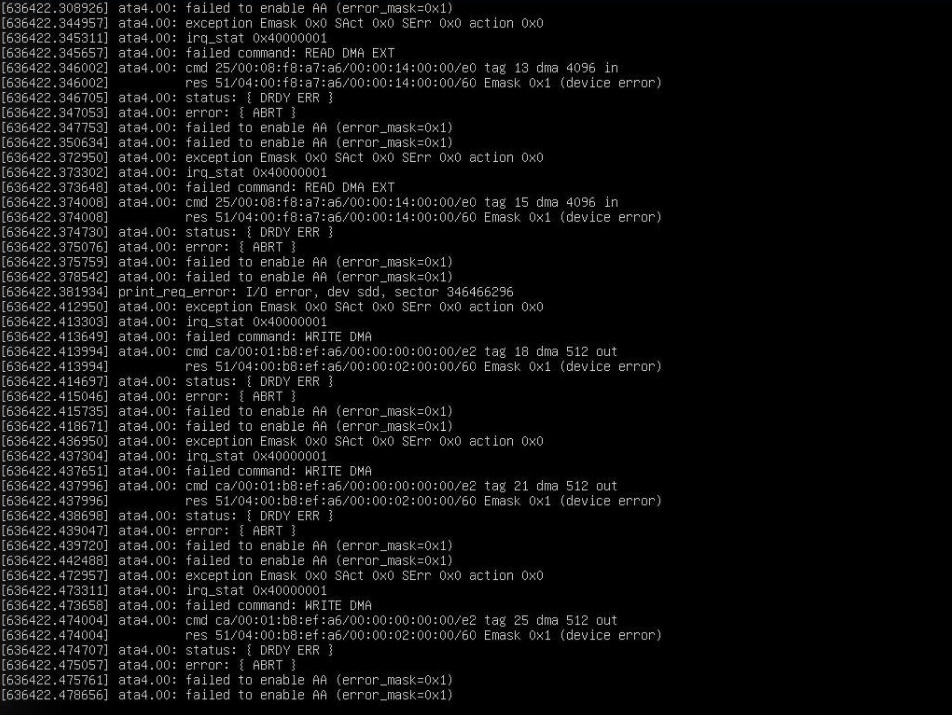
After rebooting the machine and checking cat /proc/mdstat, I saw that the “md1” RAID 10 array was resyncing. I don’t have the output saved of that nor the mdadm -D /dev/md1 output, here is the output currently after everything was fixed. The output at the time did not say that there was a “failed device”, it merely said there was only three devices in the array and the first slot said “removed” instead of “/dev/sda2”.
/dev/md1:
Version : 1.2
Creation Time : Fri Aug 30 03:10:31 2019
Raid Level : raid10
Array Size : 466493440 (444.88 GiB 477.69 GB)
Used Dev Size : 233246720 (222.44 GiB 238.84 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Fri Sep 13 23:55:50 2019
State : active
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : bitmap
Name : ubuntu-server:1
UUID : efc4aafe:326e25dd:2b9da3de:7b245123
Events : 19955
Number Major Minor RaidDevice State
4 8 2 0 active sync set-A /dev/sda2
1 8 51 1 active sync set-B /dev/sdd3
2 8 18 2 active sync set-A /dev/sdb2
3 8 34 3 active sync set-B /dev/sdc2
Then, I checked SMART info for the drive to see if it was dying and to run a “long” offline SMART test to discover any errors. Below is smartctl -a /dev/sda output:
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.15.0-62-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Crucial/Micron RealSSD C300/M500
Device Model: Crucial_CT240M500SSD1
Serial Number: 13290945F7B3
LU WWN Device Id: 5 00a075 10945f7b3
Firmware Version: MU02
User Capacity: 240,057,409,536 bytes [240 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri Sep 13 23:58:06 2019 UTC
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x85) Offline data collection activity
was aborted by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 1115) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 18) minutes.
Conveyance self-test routine
recommended polling time: ( 3) minutes.
SCT capabilities: (0x0035) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x0032 100 100 --- Old_age Always - 408
5 Reallocated_Sector_Ct 0x0032 100 100 --- Old_age Always - 32768 (0 3)
9 Power_On_Hours 0x0032 100 100 --- Old_age Always - 44978
12 Power_Cycle_Count 0x0032 100 100 --- Old_age Always - 41
170 Grown_Failing_Block_Ct 0x0032 100 100 --- Old_age Always - 30
171 Program_Fail_Count 0x0032 100 100 --- Old_age Always - 0
172 Erase_Fail_Count 0x0032 100 100 --- Old_age Always - 0
173 Wear_Leveling_Count 0x0032 100 100 --- Old_age Always - 6
174 Unexpect_Power_Loss_Ct 0x0032 100 100 --- Old_age Always - 32
181 Non4k_Aligned_Access 0x0022 100 100 --- Old_age Always - 29981 7532 22449
183 SATA_Iface_Downshift 0x0032 100 100 --- Old_age Always - 0
184 End-to-End_Error 0x0032 100 100 --- Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 --- Old_age Always - 0
188 Command_Timeout 0x0032 100 100 --- Old_age Always - 35
194 Temperature_Celsius 0x0022 055 037 --- Old_age Always - 45 (0 63 255 151 0)
195 Hardware_ECC_Recovered 0x003a 100 100 --- Old_age Always - 4294967295
196 Reallocated_Event_Count 0x0032 100 100 --- Old_age Always - 30
197 Current_Pending_Sector 0x0032 100 100 --- Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 100 --- Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 100 100 --- Old_age Always - 0
202 Percent_Lifetime_Used 0x0031 100 100 --- Pre-fail Offline - 0
206 Write_Error_Rate 0x000e 100 100 --- Old_age Always - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 44973 -
# 2 Vendor (0xff) Completed without error 00% 44972 -
# 3 Extended offline Completed without error 00% 44805 -
# 4 Short offline Completed without error 00% 44653 -
# 5 Vendor (0xff) Completed without error 00% 44627 -
# 6 Vendor (0xff) Completed without error 00% 44626 -
# 7 Vendor (0xff) Completed without error 00% 44625 -
# 8 Vendor (0xff) Completed without error 00% 44587 -
# 9 Vendor (0xff) Completed without error 00% 44576 -
#10 Vendor (0xff) Completed without error 00% 44573 -
#11 Vendor (0xff) Completed without error 00% 37362 -
#12 Vendor (0xff) Completed without error 00% 27101 -
#13 Extended offline Completed without error 00% 27041 -
#14 Vendor (0xff) Completed without error 00% 27033 -
#15 Vendor (0xff) Completed without error 00% 27027 -
#16 Vendor (0xff) Completed without error 00% 27026 -
#17 Vendor (0xff) Completed without error 00% 27024 -
#18 Vendor (0xff) Completed without error 00% 19564 -
#19 Vendor (0xff) Completed without error 00% 19548 -
#20 Vendor (0xff) Completed without error 00% 19412 -
#21 Vendor (0xff) Completed without error 00% 19397 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
The drive had passed the SMART test without any errors. Not knowing what to make of this, I added the partition back into the RAID 10 array via mdadm --manage /dev/md1 -a /dev/sda2. That went well and the RAID array resynced. The cat /proc/mdstat output matched the output shown previously.
After that I rebooted into emergency mode, ran fsck /dev/md1 -y to fix all the errors (there were quite a few) and rebooted. After that all was well… or so I thought until the same exact problem occurred again overnight last night. I can’t tell based on the above is the drive was at fault, the RAID array is mis-configured (it was installed by the provider, not myself), or something else is going on.
Any help provided would be greatly appreciated! I’m a RAID noob, so be gentle if it’s something obvious that I’m missing ![]()
Cheers!,
-Mason