I haven’t have this happening but a MX500 1TB SSD was being a ding dong on a 18.04LTS (I believe?) Ubuntu box cause of the it’s false positives on the older smartmontools versioning on that OS version.
Are you running a older OS as such that might hints at an olrder smartmontools versioning than what’s current?
Then your SMART databases might not be up to date. I would verifies if this is the case and ensures both the smartmontools and it’s databases are up to date. Before writing this off. Cause the last thing you want is misdiagnosis when your disk(s) might very well be on their ways out.
As I said MX500s were misdiagnosing on my end when the data bases were in bad versionings.
If those NVMes are failing SMART then that’s a cause for concerns. Make sure your backups are up to date, take a manual backup then ask your data center provider to replaces them at once. SMART failures might not mean the disks’ are on the way out but it usually doesn’t gets better.
I had a 500GB HDD doing this to and ever since it kept on incrementing reallocated sectors on the SMART (it would only works on short testings) so it was/is on the way out.
I still got it on me as a SHTF drive but a drive responding in this fashion shouldn’t be in service though.
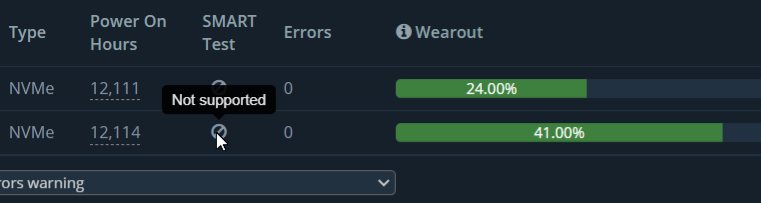
That printscreen is a diferent server than the one I was referring to when i first started this topic.
The one i was referring to looks way better, heres a printscreen.
Correct you need to confirm that you actually got the prequities installed correctly as per documentions for those NVMes. Or else they will not test properly on that end.
The above seems poorly worded, looks liek not listing th edisks is what one shoudl expect. In my case it listed the installed disk… so i’d say its correctely installed.
Really is birches on hosts who actually use TLC only disks.
SLC cache backed TLCs are MUCH better in both testings with Samsung 860 EVOs and SK Gold Hynix S31s even with reboots alone being MUCH better off on such same classed disks.
Hetzner disagrees.
I requested them to look into a replacement, they did and got back to me with…
Our test shows no issues with your drives.
-----------------%<-----------------
HDDTEST S4GENX0N420995: Ok
HDDTEST S4GENX0N421048: Ok
-----------------%<-----------------
If you means by drives not supporting S.M.A.R.T and/or live testings then…
The balls that a provider chooses to have unsupported S.M.A.R.T NVMes is really not cool if this is really the case.
We as rentees should have means to access S.M.A.R.T and other critical information from disks from a running system if at all possible.
As I said before, if a drive can’t be validly tested with trusted means then I am labeling that disk as a “questionable” disk that should be pulled from a production node as soon as possible.
Of course not. If you use any SSD it will obviously wear out. That is how it works. 25% means a quarter of the lifetime that is guarantued for has been used up. So you have 75% left to use and go for, there is no reason to change it. You would not change the tires of your car after only 25% of usage, would you?
So of course Hetzner is going to deny that change request. A (pending) raid rebuild does not automatically mean there is something wrong with the disk - especially if it is just soft raid. More likely any unclean shutdown can cause this.
TL;DR; stop worrying about the disks, there is nothing wrong with it.