MariaDB [(none)]> show global variables like 'log_error';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_error | |
+---------------+-------+
what do you mean by frozen, the service, the whole VM
is it still accessible via ssh or vnc in that state or not
can you match the timestamp to any syslog entries and is there anything after the freeze
what else is running on it other then mariadb
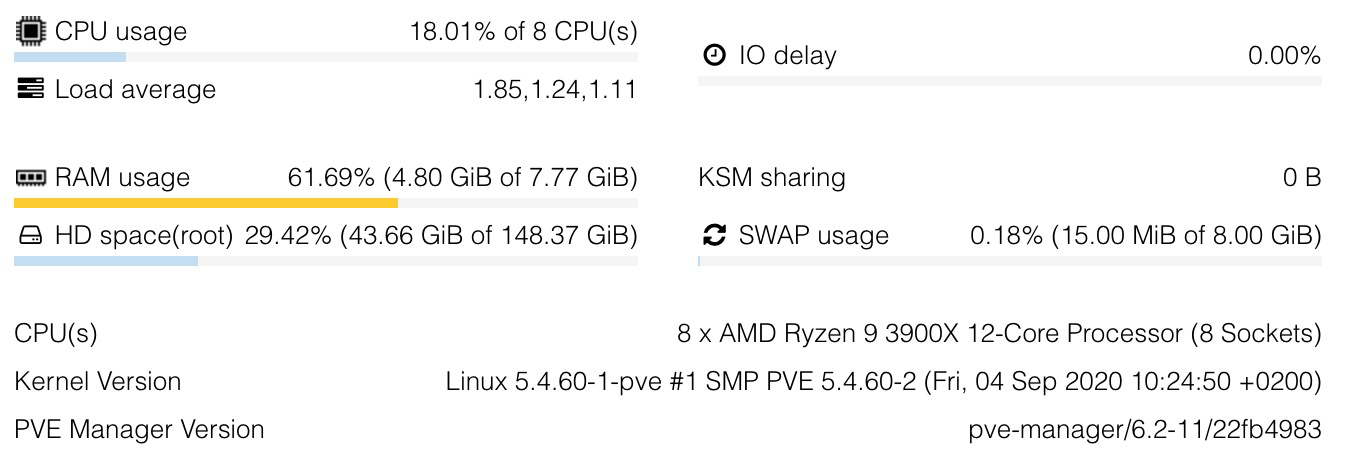
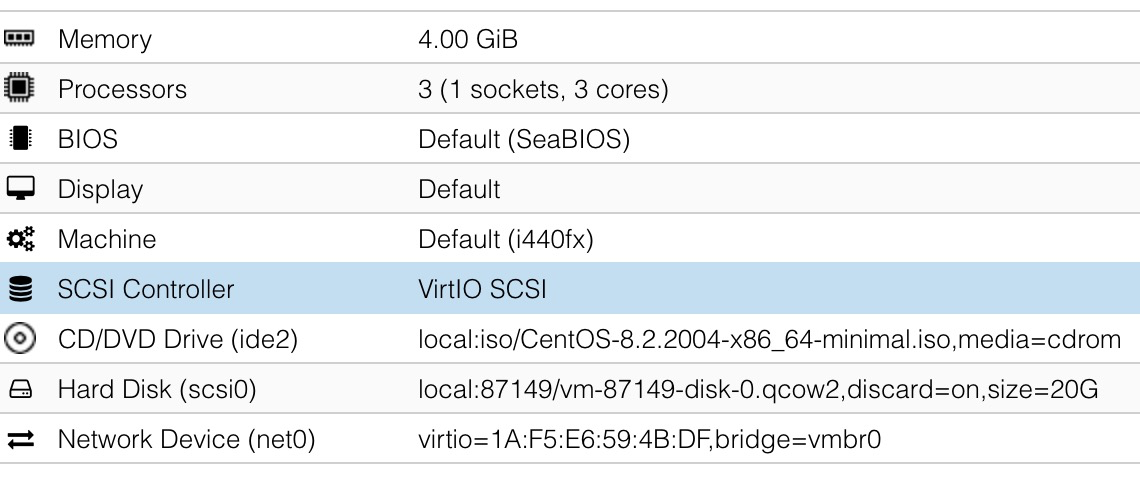
which hardware specs/options did you use, esp. for disk (thin-lvm, raid, virtio, scsi etc.?), network (virtio, local vs public ip etc.), memory (swap available?)
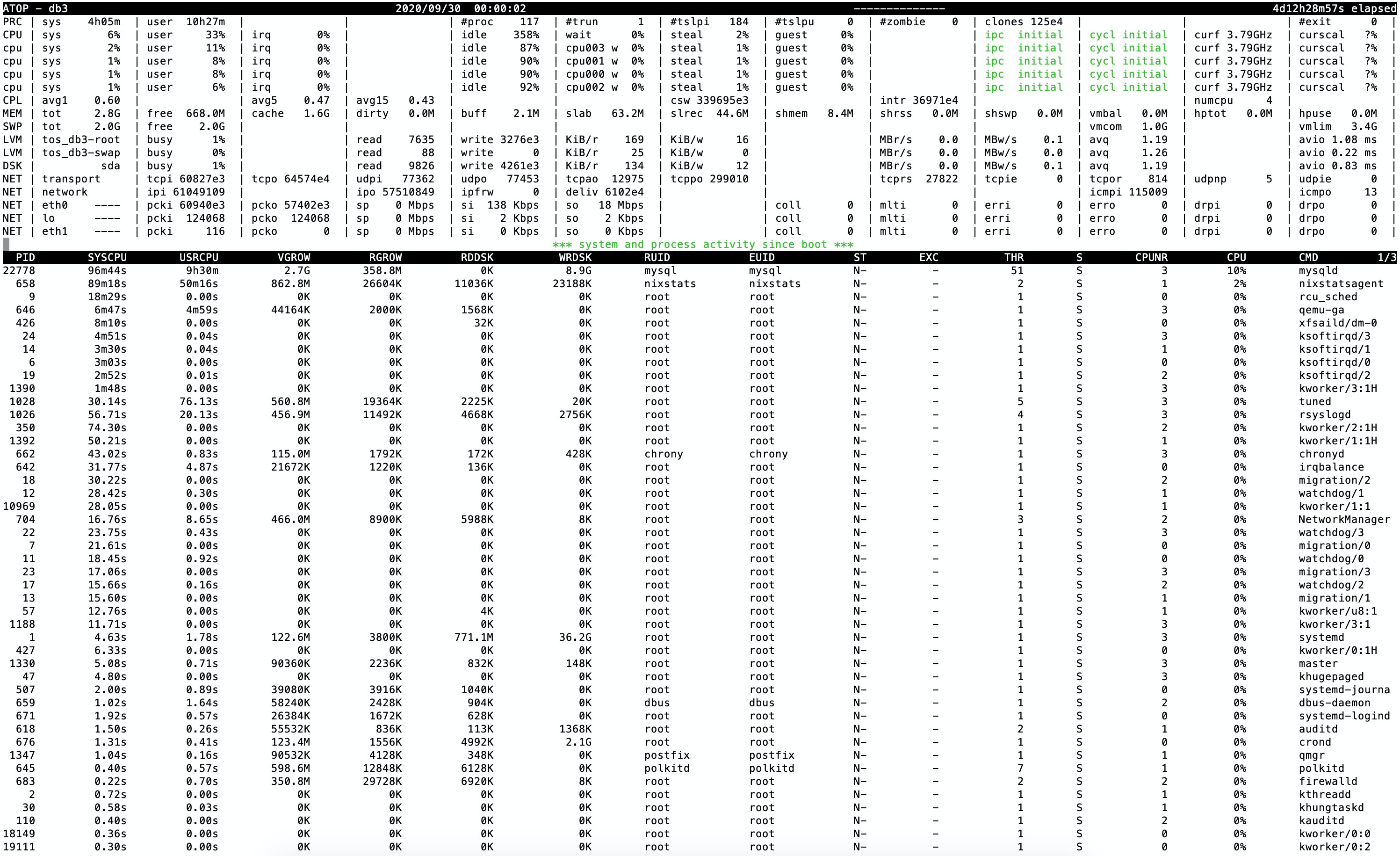
Install atop with a 30 second granularity (/etc/sysconfig/atop) to see what’s going on. Sounds like you’ve got a spike in load that you’re misattributing to MariaDB.
Next time it goes down flip through the log, atop -r /var/log/atop/atop_2020YYMMDD to see what’s happening prior to the lockup.
so you are using nested virt? (I think I now remember something in the other thread about the IPs…)
do you have other VMs running in parallel in your proxmox?
my bet would be on something like hitting IO limits or whatever. system not able to read or write properly anymore… mariadb does not has to be the direct cause as @nem already wrote. could simply add to the problem.
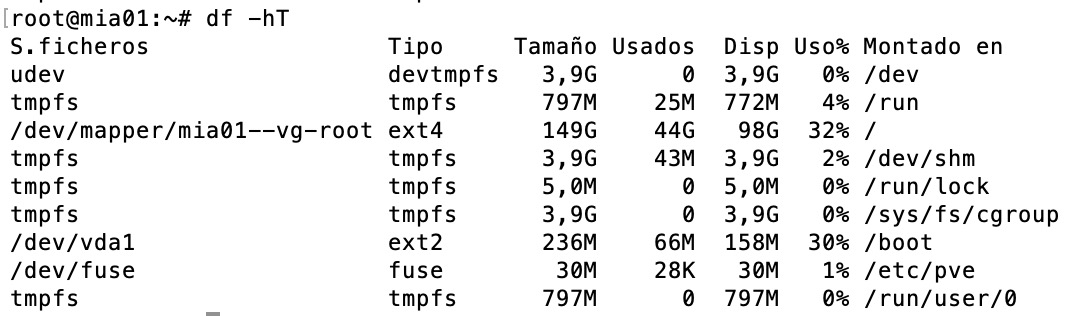
do you know what the underlying storage system is on the real hostnode? how did you setup your storage? zfs? thin-lvm? or just plain ext storage?
It’s already a production server, I can’t restart. I will need to migrate the database.
I will try to configure the logs properly in a few hours, maybe they catch something useful if it happens again. Fortunately I have another little server to use temporary.
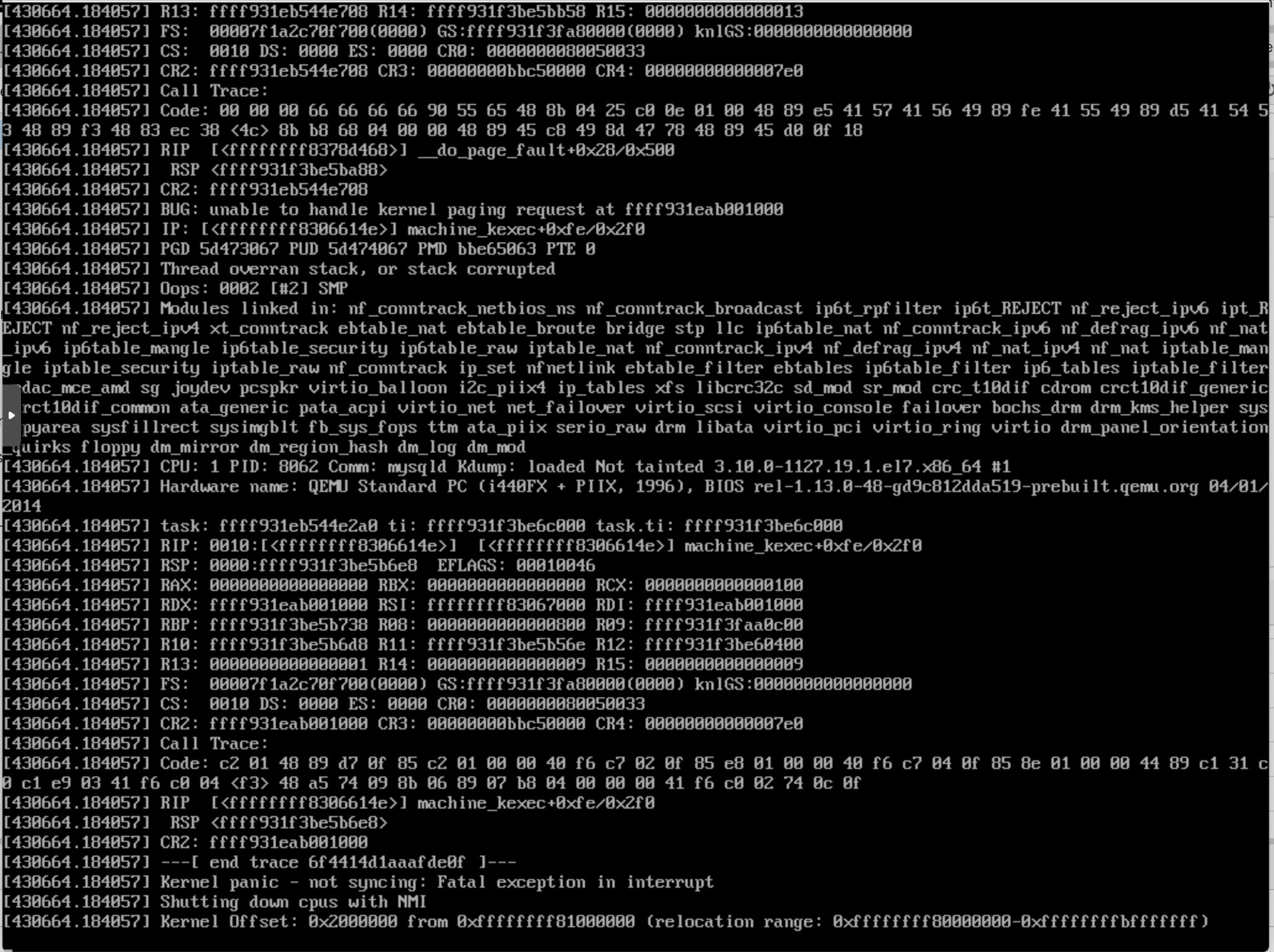
First screenshot is a kernel panic. Is your microcode up to date? Firmware? Anything tasty in /var/log/boot.log? I’ve seen bad memory for example result in sporadic panics under load. As an example, this line was enough to deduce the memory was bad.