Hi.
I’m restoring files from a BackupPC server to a VM inside a Proxmox node, using rsync. This process is causing a high load in the node and the other VMs are going down.
Any tips to get a lower load?
Hi.
I’m restoring files from a BackupPC server to a VM inside a Proxmox node, using rsync. This process is causing a high load in the node and the other VMs are going down.
Any tips to get a lower load?
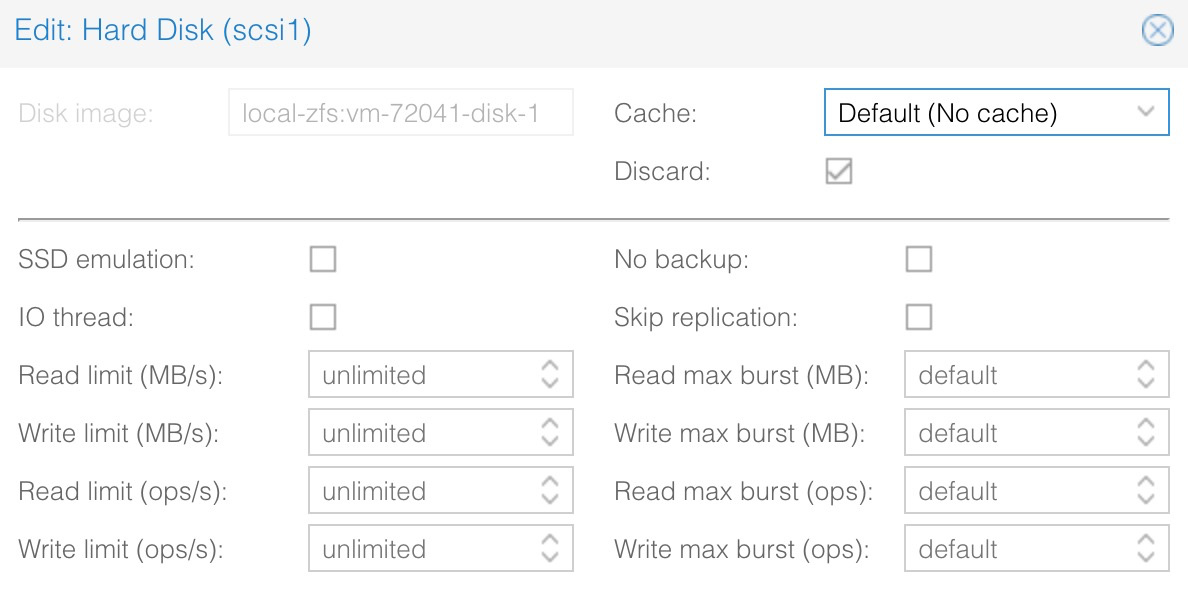
go to the ‘hardware’ tab of the vm, click on the disk and check the ‘advanced’ options, there you can set limits for disk bandwidth and/or IO including burst limits. not sure though if you might need to restart the VM then…
Can you use an IDE driver for the disk on the VM? That should slow it down nicely ![]()
Do providers put limits usually?
Depends sir. Contabo does. Some do, some doesn’t. Some will do that if they notice abusive behavior (me me me me)
Could you help me identify any errors on the disks?
Looks solid to my eyes at this hour.
If anyone has some time to help me fix this via chat or a call, send me a PM with the price please.
It is not the disk, if I am half write, it is ZFS.
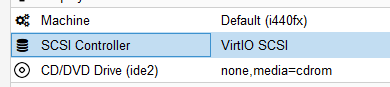
Using “VirtIO” as the SCSI Controller?
Also, you can experiment changing cache to “write back” to see if that has any improvements.
That usually helps big time with HW raid.
for the smart data I agree with @Jarland, nothing that should immediately be worrysome. however the age of these SSDs is impressive and they had their fair share already, 245TB written for the first and 175TB for the second … that’s properly used.
however, for your issues I’d rather check how the RAM and swap usage looks like, esp on the host. maybe the system swapping eats your disk bandwidth. from fio it can clearly be seen, that IOps aren’t the problem, but bandwidth is.
how does your ZFS config look like, especially the cache config, raid-level etc.
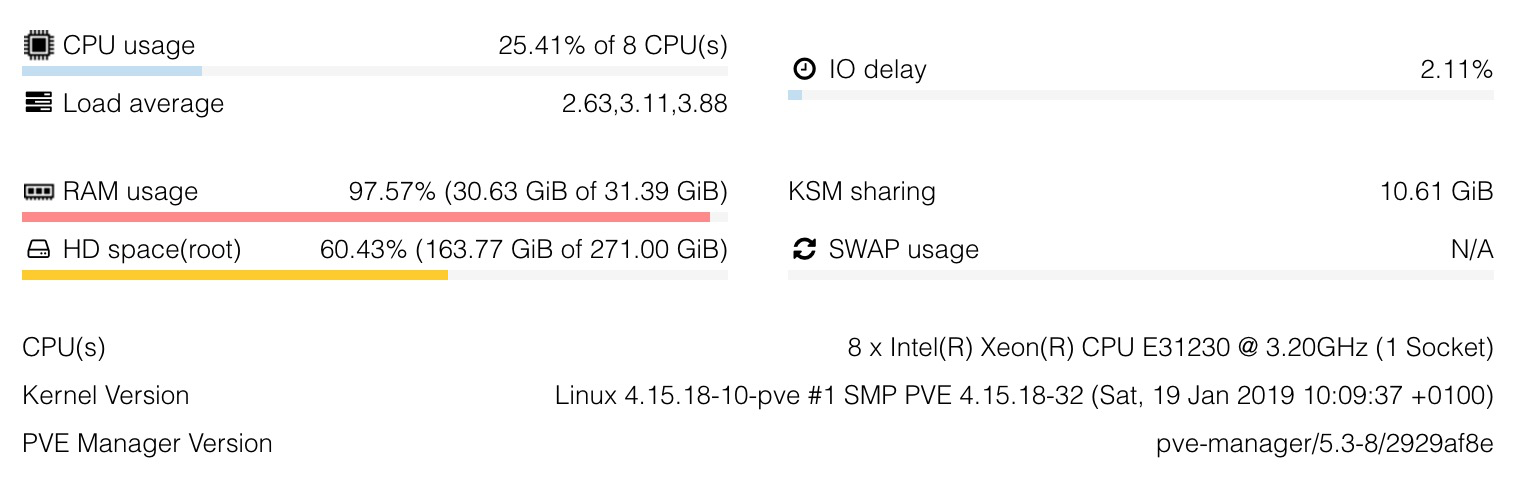
also some more information about your system won’t hurt. like cpus, ram, what do the other VMs use or do, how many of them are there, and so on…
VirtIO is.
Thanks. I’m going to try later as this is in production.
Processor : Intel(R) Xeon(R) CPU E31230 @ 3.20GHz
CPU cores : 8 @ 3492.204 MHz
AES-NI : ❌ Disabled
VM-x/AMD-V : ✔ Enabled
RAM : 31G
Swap : 0B
df: no file systems processed
Disk :
It has 5 VMs:
A. 4GB
B. 16GB
C. 1GB
D. 4GB
E. 8GB
Quite overloaded? ![]()
I can’t run YABS because load fires up and everything goes down.
your memory seems quite booked, though this could be just cache… however - no swap? I’d say that’s a very bad idea, esp. if you are close to overcommiting memory for the guests.
usually if you just restart a guest, you might end up with old memory pages, that are not needed anymore and better be swapped out. especially windows guests have a bad habit here in otherwise blocking memory.
I suggest to immediately create a swap file of 16G or better 32G and active that. also check if KSM is running, as this might also help a bit. if you can, shutdown the guests, as in stop completely and start up again only after a moment. this also might help to free up old unused memory pages…
PS: you could also use balloning esp. for the bigger guests, let’s say 12-16GB for the biggest and 6-8GB for the other. the system will then regain memory from these boxes if not needed (or just used for cache)
edit, that would bring you down just a bit below your overall memory… I just had a look at one of my boxes:
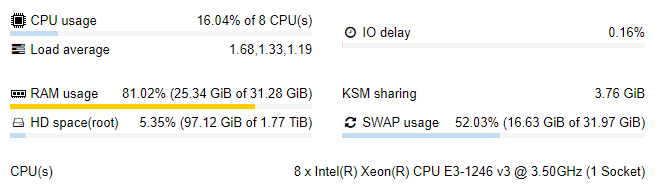
it’s about 10 guests, and the memory given to them sums up to 36GB max, but 27GB min. let ballooning and KSM do their work and all is fine.
note the amount of swap used though. that’s nothing bad, usually just old unneeded stuff ![]()
No swap is the default configuration from Proxmox ISO, IIRC. I read somewhere that swap was not good for SSD. How true is that?
I’m going to move some VMs out first and then make the experiments.
Last time I shut down a virtual machine and then couldn’t start it again because the RAM was still full.
KSM is enabled.
To add swap. Is this correct? I don’t want to break it.
# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.2G 291M 2.9G 10% /run
rpool/ROOT/pve-1 272G 164G 108G 61% /
tmpfs 16G 46M 16G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
rpool 108G 128K 108G 1% /rpool
rpool/ROOT 108G 128K 108G 1% /rpool/ROOT
rpool/data 108G 128K 108G 1% /rpool/data
/dev/fuse 30M 28K 30M 1% /etc/pve
Command I’m going to write:
zfs create -V 32G rpool/swap1
mkswap /dev/zvol/rpool/swap1
swapon /dev/zvol/rpool/swap1
# add to /etc/fstab :
echo "/dev/zvol/rpool/swap1 none swap sw 0 0" >> /etc/fstab
I don’t know if /dev/zvol is correct. I shouldn’t have used ZFS.
imho that should work. you can check if the pool rpool exists in /dev/zvol simply via ls ![]()
I never used the proxmox ISO though and rarely use zfs at all…
if unsure, you of course could create just an empty file somewhere via dd and use that as swapfile. at least for testing purposes that should be quite easy.
also if in doubt, don’t put the fstab line in. you can always manually activate swap after a reboot. just to make sure the system does not get stuck during boot by not finding the swap partition or volume etc.
Seeing your uptime I just remembered something else… sometimes I see the pveproxy process get stuck and you will end up having quite some processes in ps like that:
www-data 17556 0.0 0.0 567144 3096 ? S 2019 10:49 pveproxy worker (shutdown)
www-data 17557 0.0 0.0 567144 3132 ? S 2019 10:44 pveproxy worker (shutdown)
www-data 23890 0.0 0.0 567116 3076 ? S 2019 10:10 pveproxy worker (shutdown)
that could also be hogging your ram and making things worse. pveproxy essentially is the webserver for the control panel itself, so stopping it for a moment via service pveproxy stop and after that starting it up again, won’t hurt but hopefully also get rid of orphaned sh*t and free up some memory…