So I worked this out… Wow, that was a journey. At least now I have some interesting content for a blog post 
Linux updates the load average every 5 seconds. In fact, it actually updates every 5 seconds plus one “tick”
sched/loadavg.h:
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
sched/loadavg.c
* The global load average is an exponentially decaying average of nr_running +
* nr_uninterruptible.
*
* Once every LOAD_FREQ:
*
* nr_active = 0;
* for_each_possible_cpu(cpu)
* nr_active += cpu_of(cpu)->nr_running + cpu_of(cpu)->nr_uninterruptible;
*
* avenrun[n] = avenrun[0] * exp_n + nr_active * (1 - exp_n)
HZ is the kernel timer frequency, which is defined when compiling the kernel. On my system, it’s 250:
% grep "CONFIG_HZ=" /boot/config-$(uname -r)
CONFIG_HZ=250
This means that every 5.004 seconds (5 + 1/250), Linux calculates the load average. It checks how many processes are actively running plus how many processes are in uninterruptable wait (eg. waiting for disk IO) states, and uses that to compute the load average, smoothing it exponentially over time.
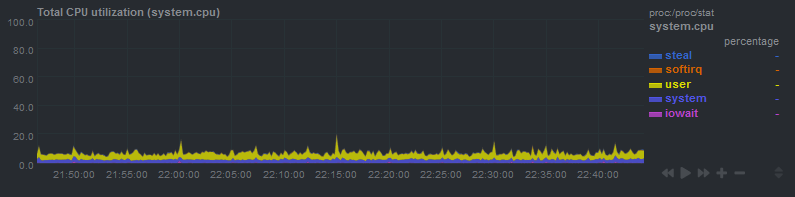
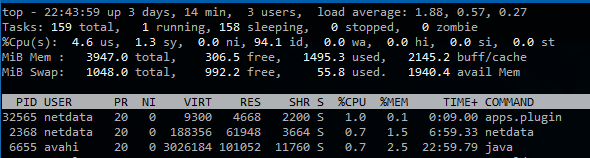
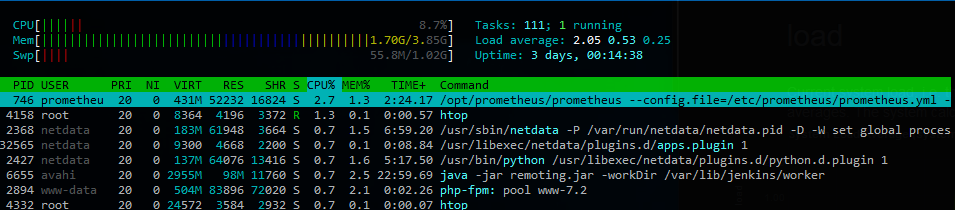
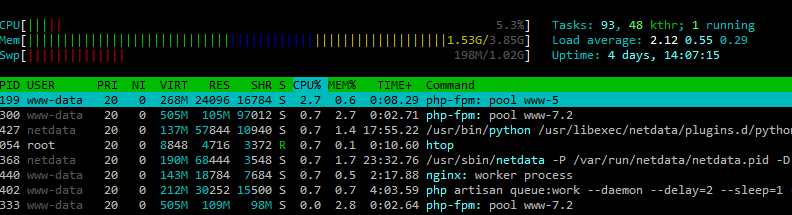
Say you have a process that starts a bunch of subprocesses every second. For example, Netdata collecting data from some apps. Normally, the process will be very fast and won’t overlap with the load average check, so everything is fine. However, every 1251 seconds (5.004 * 250), the load average update interval will be an exact multiple of one second. 1251 seconds is 20.85 minutes, which is exactly the interval I was seeing the load average increase. My educated guess here is that every 20.85 minutes, Linux is checking the load average at the exact time that several processes are being started and are in the queue to run.
I confirmed this by disabling netdata and manually watching the load average:
while true; do uptime; sleep 5; done
After 1.5 hours, I did not see any similar spikes. The spikes only occur when Netdata is running.
So… in the end… The app that I was using for monitoring the load was the one responsible for causing it. Ironic. He could save others from death, but not himself.
It turns out other people have hit similar issues in the past, albeit with different intervals. The following posts were extremely helpful:
Reported it to the Netdata devs here: Netdata causing load average increase every ~20 minutes · Issue #5234 · netdata/netdata · GitHub. In the end, I’m not sure if I’d call this a bug, but perhaps netdata could implement some jitter so that it doesn’t perform checks every one second exactly.